
最近有一些讀者跟學員來信,跟我說他們想要學習怎麼預測庫存,他們的問題可能是:
- 是倉庫人員,希望可以提早依據不同的活動類型,提早準備貨量
- 是行銷人員,希望可以預測自己舉辦的不同行銷活動,會銷售多少?
為什麼要預估貨量、預測業績或銷量?
不論是預估貨量、預測業績,這些問題的底層邏輯都是一樣的,我來拆解一下給大家看:
- 目標:希望可以知道 A 商品,在不同情況下的銷售狀況
- 背景:我們有過去不同行銷活動下的 A 商品銷售情況 (過去的數據)
- 預測:利用過去的數據,對未來做預測,預測銷售量、單量、或是預計可能會銷售的貨量,讓每個部門的人都可以提前做好準備
預估貨量、預測業績,都是為了可以讓不同部門的人,可以更好的做好萬全準備,以應付未來可以預知的狀況 (因為過去做過類似的事情,所以可以透過過去預估未來)
怎麼預估貨量或是預測業績?3 個核心步驟分享
步驟一:準備好過去的資料
- 這邊的資料準備,會需要你有一定的 excel 或是 sql 基礎
- 你會準備的資料維度包括 X (自變數) 跟 Y (應變數),X 的值會影響 Y 的結果:
- 品項
- X:無活動時的銷量
- X:有活動時的銷量 (可以分 A 活動、B 活動)
- Y:實際銷量
- 無活動時的銷量應該怎麼估算?
- 可以用過去幾天的平均,以反映最新的狀況
- 有活動時的銷量應該怎麼估算?
- 可以用過去相似時間的銷量,以反映最新的狀況
步驟二:以線性回歸模型來檢測準確度
- 這邊會需要一點點 python 的基礎,以完成線性回歸模型的架設
- 一開始會需要將步驟一的資料讀進去
- 接著,X 是自變數,Y 是結果,我們要丟到模型中訓練,並且確認一下用線性回歸預測銷量的準確度 (每個案例的準備度有所不同,請自行評估)
- 用散佈圖、實際值及預測值之間的殘差分佈圖、R 平方來判斷線性回歸預測銷量的準確度
步驟三:準備結論以及行動方案
- 如果模型可以用,就可以準備做總結及行動方案
- 合作部門怎麼用這個模型?
- 什麼樣的貨種適合這個模型?(可以搭配其他商業分析的思維來下結論)
Python 實作分享:用線性回歸模型來預測貨量、業績、銷量
- 這次會使用 Google Colab,不用下載任何程式,只要有 Gmail 帳號就可以用
- 如果還不太熟,可以看一下:Google Colab:以 Python 3 分鐘完成資料匯入及分析 (含範例檔案)
1. 匯入套件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import csv
# 匯入套件並且執行 Google 帳號驗證
# 查看gspread版本
# ref: <https://cyublog.com/articles/python-zh/colab-tutorial-google-spreadsheet/>
import gspread
print(gspread.__version__)
# 執行驗證
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
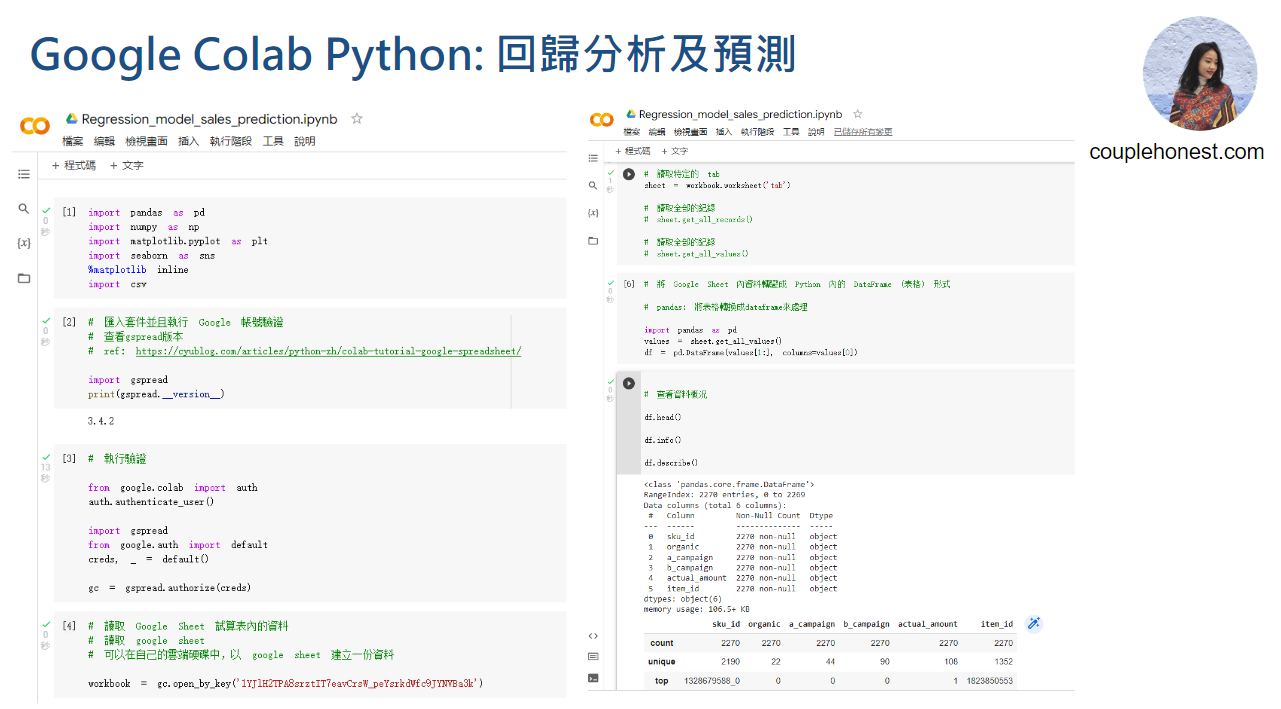
2. 匯入資料、轉資料格式 (data_type)
# 讀取 Google Sheet 試算表內的資料
# 讀取 google sheet
# 可以在自己的雲端硬碟中,以 google sheet 建立一份資料
workbook = gc.open_by_key('1YJlH2TPA8srztIT7eavCrsW_peYsrkdWfc9JYNVBa3k')
# 讀取特定的 tab
sheet = workbook.worksheet('tab')
# 將 Google Sheet 內資料轉變成 Python 內的 DataFrame (表格) 形式
# pandas: 將表格轉換成dataframe來處理
import pandas as pd
values = sheet.get_all_values()
df = pd.DataFrame(values[1:], columns=values[0])
# 查看資料概況
df.head()
df.info()
df.describe()
# 處理一下 data type
df["organic"] = df["organic"].astype("float")
df["a_campaign"] = df["a_campaign"].astype("float")
df["b_campaign"] = df["b_campaign"].astype("float")
df["actual_amount"] = df["actual_amount"].astype("float")
df.info()
3. 重頭戲:開始做線性回歸模型
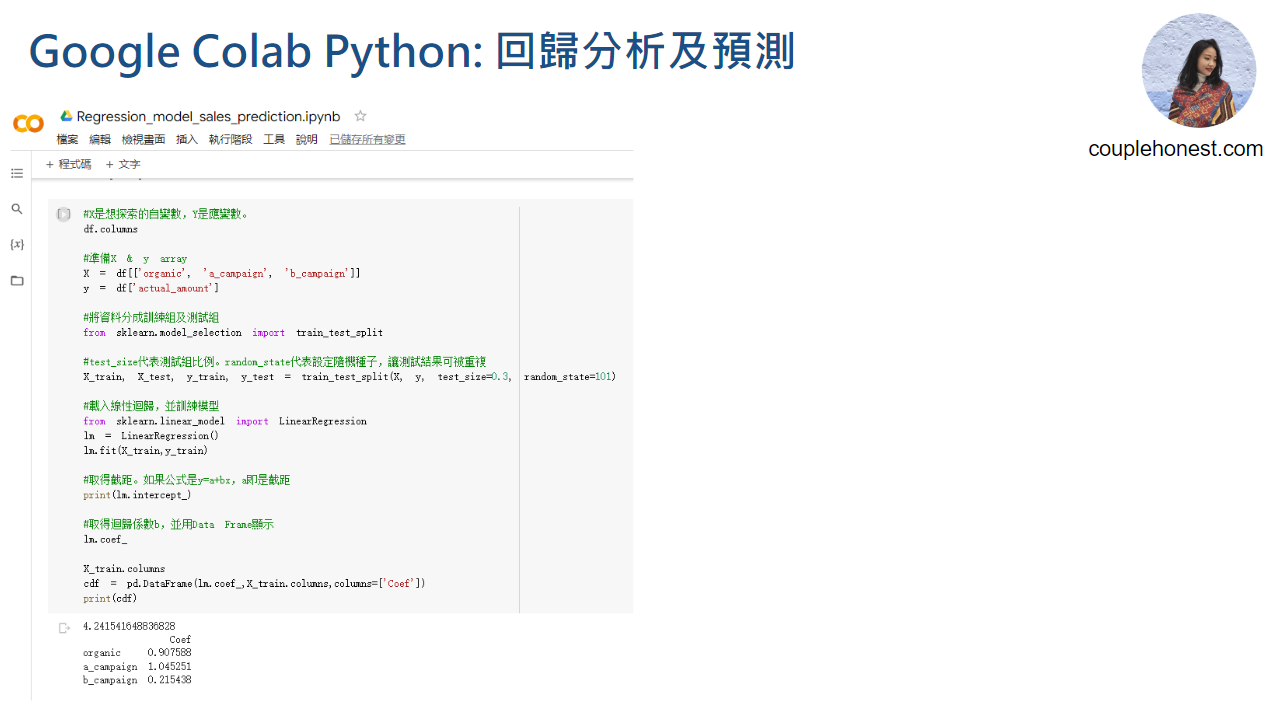
# X 是想探索的自變數,Y 是應變數 (結果)
df.columns
# 準備 X & y array
X = df[['organic', 'a_campaign', 'b_campaign']]
y = df['actual_amount']
# 將資料分成訓練組及測試組
from sklearn.model_selection import train_test_split
# test_size代表測試組比例,random_state 代表設定隨機種子,讓測試結果可被重複
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
# 載入線性迴歸,並訓練模型
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train,y_train)
# 取得截距:如果公式是 y=a+bx,a 就是截距
print(lm.intercept_)
# 取得迴歸係數 b,並用 Data Frame 顯示
lm.coef_
X_train.columns
cdf = pd.DataFrame(lm.coef_,X_train.columns,columns=['Coef'])
print(cdf)
4. 用三個方式檢查模型的準確度:散佈圖、殘差分佈圖、R 平方
#比較實際跟預測之間的差距
plt.scatter(y_test,predictions)
# 看實際值及預測值之間的殘差分佈圖
predictions = lm.predict(X_test)
predictions
sns.distplot((y_test-predictions))
# R 平方
r2 = lm.score(X_test,y_test)
print ('R^2 = %.2f'%r2)
如何用預測模型影響決策?結論及行動方案分享!
結論:簡單解釋模型如何幫助我們解決問題
- 背景、目標解釋
- 資料集如何準備的
- 選擇什麼模型 (回歸模型) 進行訓練
- 模型準度為何
- 以商業分析角度分析:什麼樣的貨種的準確度最高?(用 excel, sql 統計)
行動方案:跨部門怎麼使用
- 以商業分析角度思考:什麼情況下可以使用模型?
- 跨部門使用方式解釋
結論:這次的案例非常經典,走過一遍典型的預測流程
- 這是很典型在業界會碰到的狀況:預測貨量、預測業績
- 因此如果你希望你的專案或是作品集可以應用這樣的流程,來嘗試看看做預測模型
- 可以點擊下方下載完整的數據練習包、完整的程式碼 (Python code)、以及最終結論及行動方案的簡報 (故事線)


![Read more about the article [數據分析#3] google sheet filter() 使用方法](https://i0.wp.com/couplehonest.com/wp-content/uploads/2020/07/google-sheet-filter.png?fit=300%2C179&ssl=1)
Pingback: [數據分析#0] 數據分析文章導覽 - Lisa Wu 理紗豆苗工作室